Preface¶
Intention¶
There are several needs that led to the creation of the HCP SDK:
- Blueprint implementation of a connector module to access HCPs authenticated namespaces in a language that is easy enough to understand for any developers, whatever language she/he normally uses, to provide a base for own development.
- Showcase for coding guidelines outlined below.
- Demonstration material for developer trainings.
- And last, but not least, a replacement for the various modules the author used in the past for his own coding projects.
About HCP¶
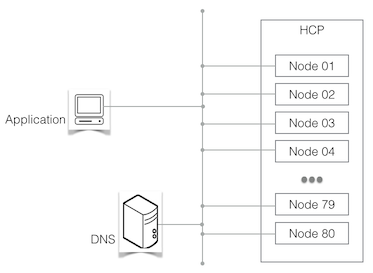
A simple HCP environment
Hitachi Content Platform (HCP) is a distributed object storage system designed to support large, growing repositories of fixed-content data. An HCP system consists of both hardware (physical or virtual) and software.
HCP stores objects that include both data and metadata that describes that data. HCP distributes these objects across the storage space. HCP represents objects either as URLs or as files in a standard file system. An HCP repository is partitioned into namespaces. Each namespace consists of a distinct logical grouping of objects with its own directory structure. Namespaces are owned and managed by tenants.
HCP provides access to objects through a variety of industry-standard protocols, as well as through a native http[s]/reST interface.
Focus¶
hcpsdk primarily focuses on HCP version 3 and above, and the authenticated Namespaces invented with version 3.
For using hcpsdk with the Default Namespace, see Appendix 1.
Coding for HCP¶
Even as HCP might behave like a web server at first glance, it has some very different characteristics when it comes to coding against it, using one of the http/reST based interfaces (native http/reST, HS3 and HSwift). This isn’t really relevant for an application doing a single request from time to time, but it is critical for an application designated for high load / high performance HCP access.
To create an application optimized for optimal HCP access for the latter case:
- Use threading or multiprocessing to access HCP using multiple connections in parallel
- Use all available nodes, in conjunction with (1.)
- Keep connections persistent, as connection setup is an expensive operation, especially when using https. Nevertheless, release connections if unused for some time, as one should not block an HCP connection slot permanently without using it.
- If there’s no urgent need for an human-readable structure, use a structure optimized for HCP, as demonstrated with the hcpsdk.pathbuilder — unique object names subpackage
There are some additional suggestions not aiming at performance, but for reliability:
- If there is no load balancer in the data path to HCP, cache HCPs IP addresses in the application and use them to access all nodes in a round-robin fashion. Refresh the cached address pool from time to time and on a failed Connection, too. Depending on how HCP has been integrated with the corporate DNS, this can lower network traffic overhead significantly.
- If there is a replication target HCP, make the application replica-aware - at least, allow the application to read from the replica.
- As a last resort, make sure the application can survive some time of not being able to connect to HCP by caching content locally to a certain degree (this is not covered by this SDK).
Using the proper URL¶
hcpsdk tries to be as open as possible - that’s why it doesn’t pretend URLs prefixed for the various gateways HCP offers. The same is true for headers that are required for various request (espacially for HSwift and MAPI). It’s up to you to use the correct URL for the gateway used, as well as to add headers where required. You might want to consult the HCP manuals for the details.
For convenience, here are the mainly used URLs:
native http(s)/REST to an authenticated Namespace:
FQDN: namespace.tenant.hcp.dom.comURL: /rest/<your>/<folders>/objectnative http(s) to the default Namespace:
FQDN: default.default.hcp.dom.comURL: /fcfs_data/<your>/<folders>/objector, if metadata access is needed:URL: /fcfs_metadata/<your>/<folders>/object/metafileHSwift http(s)/REST to an authenticated Namespace:
FQDN: api.hcp.dom.comURL: /swift/v1/<tenant>/<namespace>/<your>/<folders>/objecthttp(s)/REST to MAPI:
FQDN: admin.hcp.dom.com(when using a system level user)-or-FQDN: <tenant>.hcp.dom.com(when using a tenant level user)URL: /mapi/<endpoint>